开篇:APP中的下载模块,其实也算一个网络访问的模块,但又和一般的后台接口之类网络请求不太一样。而且到目前为止,类似okhttp,volley之类的接口请求框架非常丰富,下载模块总会让开发者去花更多心思去完善流程。
现在没有网络请求的APP已经少得可怜了,相比之下下载显得不是那么必须,但是在一个相对成熟的APP中,不管是数据库,还是下载都是必不可缺的,说多了都是废话,还是进入正题好了。
PS:本文依旧以实现功能为导向,不对具体原理做深入解释,相关请自己百度谷歌一下。
1.从上至下
从原理开始分析总觉得很容易让人迷惑,不妨从应用的层面上来分解这个问题(后面遇到坑再填好了),先来看看Demo的界面:
界面不要太简单有木有。
功能是这样的,这个APP一启动起来在onCreate里面就会下载一个文件,当然是在后台log打进度日志啦,点击暂停就暂停下载,点击继续续传下载,当然如果完全退出APP甚至是重启手机也是可以断点续传的。点击开始下载2并不会影响上一个下载。
好了可以开始看代码了:
String appUrl = "http://music.baidu.com/cms/BaiduMusic-pcwebdownload.apk";
String downloadPath = Environment.getExternalStorageDirectory() + "/BaiduMusic-pcwebdownload.apk";
upgradeTaskId = DownLoadManager.getInstance(getApplicationContext()).addTask(null, appUrl, downloadPath, true, this);
Log.d("kkkkkkkk", "initData upgradeTaskId --> " + upgradeTaskId);
以上代码是在onCreate里面做的,也就是说页面启动的时候就添加了一个下载任务,在这里的逻辑也就是开始下载了。
看到了那个醒目的DownLoadManager了吗,里面有很多东西,不妨来慢慢分解它:
private DownLoadManager(Context context) {
mContext = context;
mPool = new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIUM_POOL_SIZE, KEEP_LIVE_TIME, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(QUEUE_SIZE));
}
public static DownLoadManager getInstance(Context context) {
if (mInstance == null) {
synchronized (DownLoadManager.class) {
if (mInstance == null) {
mInstance = new DownLoadManager(context);
}
}
}
return mInstance;
}
作为一个manager,单例是基本素养,就不多说了,来看构造函数里面的几个东东。context主要用到了3个地方,1是创建数据库,2是https获得证书,3是注册广播。什么?为啥有数据库?没有数据库怎么牛逼地断点续传呢·····先剧透到这里,接着看mPool,这个是一个线程池,每一个下载相当于从这个线程池里捞出线程来执行下载任务,里面这几个参数private static final int CORE_POOL_SIZE = 5;
private static final int MAXIUM_POOL_SIZE = 10;
private static final int KEEP_LIVE_TIME = 30;
private static final int QUEUE_SIZE = 2000;
先看看就行了。
首先来看看addTask的实现
public String addTask(String uid, String url, String path, boolean isSupportBreakpoint, DownLoadCallBack callBack) {
Log.d(TAG, "url=" + url);
Log.d(TAG, "path=" + path);
String taskId = getTaskId(uid, url, path);
Log.d(TAG, "taskId=" + taskId);
DownLoader downLoader = findTask(uid, taskId, true);
if (downLoader == null) {
String fileName = path.substring(path.lastIndexOf("/") + 1);
String filePath = path.substring(0, path.lastIndexOf("/"));
Log.d(TAG, "fileName=" + fileName);
Log.d(TAG, "filePath=" + filePath);
DownLoadBean info = new DownLoadBean();
if (TextUtils.isEmpty(uid)) {
uid = "12345";// UserManager.getCurUserId();
}
info.setUserID(uid);
info.setTaskID(taskId);
info.setFilePath(filePath);
info.setFileName(fileName);
info.setIsSupportBreakpoint(isSupportBreakpoint);
info.setUrl(url);
downLoader = new DownLoader(mContext, info, mPool, true);
mDownLoaderList.put(taskId, downLoader);
} else {
if (!mDownLoaderList.containsKey(taskId)) {
mDownLoaderList.put(taskId, downLoader);
}
}
registReceiver();
downLoader.setDownLoadCallBack(callBack);
if (!downLoader.isDownLoading()) {
downLoader.start();
}
return taskId;
}
从基本的流程来捋一遍吧,首先是把uid, url, path这三个参数通过getTaskId方法生成一个taskId,其实就是拼起来md5了一下:
private String getTaskId(String uid, String url, String path) {
return StringUtil.md5(uid + url + path);
}
加密算法如下,不解释啦:
public static String md5(String s) {
char hexDigits[] = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f' };
try {
byte[] strTemp = s.getBytes();
// 使用MD5创建MessageDigest对象
MessageDigest mdTemp = MessageDigest.getInstance("MD5");
mdTemp.update(strTemp);
byte[] md = mdTemp.digest();
int j = md.length;
char str[] = new char[j * 2];
int k = 0;
for (int i = 0; i < j; i++) {
byte b = md[i];
// 将每个数(int)b进行双字节加密
str[k++] = hexDigits[b >> 4 & 0xf];
str[k++] = hexDigits[b & 0xf];
}
return new String(str);
} catch (Exception e) {
return null;
}
}
然后回去通过findTask去找数据库中是否有对应DownLoader,如果有的话直接把它放到mDownLoaderList中然后调用DownLoader的start方法,如果没有我们继续看。
这里有个实体类DownLoadBean来存放下载的相关信息,有必要来先看看里面的字段:
private String userID;
private String taskID;
private String url;
private String filePath;
private String fileName;
private long fileSize;
private long downloadSize;
private boolean isSupportBreakpoint;
从名字上基本可以望文生义了,不需要太多解释吧。刚刚说到如果findTask的DownLoader是空的,证明是第一次下载这个任务,那么需要重新构造下载相关信息。从代码上可以看出来除了fileSize和downloadSize没法构造其他的都可以直接塞进去了,最后通过downLoader = new DownLoader(mContext, info, mPool, true);来生成一个新的DownLoader,然后后面就跟从数据库中找到一样操作了。无非就是加入到一个list中去方便管理,和开启下载任务。当然还有一个registReceiver方法,先看看吧,顺便把反注册也贴上来了:
private void registReceiver() {
if (mNetStateBroadCastReceiver == null) {
mNetStateBroadCastReceiver = new NetStateReceiver();
IntentFilter filter = new IntentFilter();
filter.addAction(ConnectivityManager.CONNECTIVITY_ACTION);
mContext.registerReceiver(mNetStateBroadCastReceiver, filter);
}
}
private void unRegistReceiver() {
if (mDownLoaderList.isEmpty() && mNetStateBroadCastReceiver != null) {
mContext.unregisterReceiver(mNetStateBroadCastReceiver);
mNetStateBroadCastReceiver = null;
}
}
注册了一个监听网络状态变化的广播监听器:
public class NetStateReceiver extends BroadcastReceiver {
@Override
public void onReceive(Context context, Intent intent) {
ConnectivityManager manager = (ConnectivityManager) context.getSystemService(Context.CONNECTIVITY_SERVICE);
NetworkInfo networkInfo = manager.getActiveNetworkInfo();
if (networkInfo != null) {
if (networkInfo.isAvailable()) {
if (networkInfo.getType() == ConnectivityManager.TYPE_WIFI) {
DownLoadManager.getInstance(context).startAllTask();
} else {
DownLoadManager.getInstance(context).stopAllTask();
}
} else {
DownLoadManager.getInstance(context).stopAllTask();
}
} else {
DownLoadManager.getInstance(context).stopAllTask();
}
}
}
大概意思就是在wifi环境下所有任务自动下载,非wifi环境和断网下自动停止,真是好人性化好贴心好不做作,跟外面那些妖艳贱货完全不一样,当然这个根据自己的业务自己去处理这种逻辑才是王道呢科科。
广播监听器里面方法有startAllTask和stopAllTask,看看里面都干了些什么:
public void startAllTask() {
Set<Entry<String, DownLoader>> set = mDownLoaderList.entrySet();
Iterator<Entry<String, DownLoader>> iterator = set.iterator();
while (iterator.hasNext()) {
Entry<String, DownLoader> entry = iterator.next();
DownLoader downLoader = entry.getValue();
if (downLoader != null && !downLoader.isDownLoading()) {
downLoader.start();
}
}
}
public void stopAllTask() {
Set<Entry<String, DownLoader>> set = mDownLoaderList.entrySet();
Iterator<Entry<String, DownLoader>> iterator = set.iterator();
while (iterator.hasNext()) {
Entry<String, DownLoader> entry = iterator.next();
DownLoader downLoader = entry.getValue();
if (downLoader != null && downLoader.isDownLoading()) {
downLoader.stop();
}
}
unRegistReceiver();
}
知道刚刚为什么要把DownLoader都塞到mDownLoaderList里面去了吧,好了马上要进入下一步了,分析到现在很明显了,所有的下载核心都封装在一个DownLoader类中,每一个下载都对应一个DownLoader,它们被装在一个mDownLoaderList的容器里方便管理。
2.DownLoader初探
刚刚我们看到,新建一个新的下载任务会用downLoader = new DownLoader(mContext, info, mPool, true);来创建一个新的DownLoader,那么从构造函数开始吧:
public DownLoader(Context context, DownLoadBean sqlFileInfo, ThreadPoolExecutor pool, boolean isNewTask) {
mContext = context;
mSQLDownLoadInfo = sqlFileInfo;
mPool = pool;
mIsSupportBreakpoint = sqlFileInfo.isSupportBreakpoint();
mUrl = mSQLDownLoadInfo.getUrl();
mFileSize = mSQLDownLoadInfo.getFileSize();
mDownLoadSize = mSQLDownLoadInfo.getDownloadSize();
mFilePath = mSQLDownLoadInfo.getFilePath();
mFileName = mSQLDownLoadInfo.getFileName();
mHelper = DownloadTaskDBHelper.getInstance(context);
if (isNewTask) {
mHelper.save(sqlFileInfo);
}
}
用参数初始化了一堆变量,反正就放那里没错啦,然后创建了一个DownloadTaskDBHelper实例,我们先把mHelper当黑盒好了,后面再专门看看这个数据库是怎么设计与实现的。
既然构造函数没有什么,那么看看start方法吧:
public void start() {
if (mDownLoadTask == null) {
mDownLoadTask = new DownLoadTask();
}
mPool.execute(mDownLoadTask);
ondownload = true;
mHandler.sendEmptyMessage(TASK_START);
}
先看最后一句话,是一个handler的消息,其实用来回调的:
private Handler mHandler = new Handler(Looper.getMainLooper()) {
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
if (mDownLoadCallBack != null) {
if (msg.what == TASK_START) { // 开始下载
mDownLoadCallBack.onStart(getTaskID());
} else if (msg.what == TASK_STOP) { // 停止下载
mDownLoadCallBack.onStop(mFileSize, mDownLoadSize, getTaskID());
if (mDownLoadSize == 0) {
mDownLoadCallBack = null;
}
} else if (msg.what == TASK_PROGESS) { // 改变进程
mDownLoadCallBack.onLoading(mFileSize, mDownLoadSize);
} else if (msg.what == TASK_ERROR) { // 下载出错
String error_msg = msg.getData().getString(ERROR_KEY);
mDownLoadCallBack.onFailure(error_msg);
} else if (msg.what == TASK_SUCCESS) { // 下载完成
mDownLoadCallBack.onSuccess(mFilePath + File.separator + mFileName, getTaskID());
mDownLoadCallBack = null;
}
}
}
};
再来看看接口的定义:
public interface DownLoadCallBack {
void onStart(String taskID);
void onLoading(long total, long current);
void onSuccess(String path, String taskID);
void onFailure(String msg);
void onStop(long total, long current, String taskID);
}
这些回调主要是让使用着知道下载状态,虽然必须但没啥好说的,现在把代码贴出来主要是后面看到相关代码懵逼。
好了我们现在回到start方法,新建了一个DownLoadTask并且使用线程池来执行了它,DownLoadTask是一个runnable,也就是下载的具体实现了,来来来接着看。DownLoadTask里面的run方法就只有一个download方法,看来这是下载的全部东东了,先贴出来分析下:
private void downLoad() {
if (mDownLoadSize == mFileSize && mFileSize > 0) {// 如果下好的文件大小与文件本身大小一样,则默认已经下载完成,不再下载
ondownload = false;
mHandler.sendEmptyMessage(TASK_PROGESS);
mDownLoadTask = null;
return;
}
ConnectionWrapperManager manager = null;
InputStream inputStream = null;
try {
manager = new ConnectionWrapperManager(mContext, mUrl);
manager.setRequestMethod(DownLoadManager.RequsteMethod.GET);
manager.setConnectTimeout(CONNECT_TIME_OUT);
manager.setReadTimeout(READ_TIME_OUT);
if (mDownLoadSize < 1) {// 第一次下载,初始化
openConnention(manager);
} else {
if (new File(mFilePath + File.separator + mFileName + ".tmp").exists()) {
mLocalFile = new RandomAccessFile(mFilePath + File.separator + mFileName + ".tmp", "rwd");
mLocalFile.seek(mDownLoadSize);
manager.setRequestProperty("Range", "bytes=" + mDownLoadSize + "-");
} else {
mFileSize = 0;
mDownLoadSize = 0;
openConnention(manager);
saveDownloadInfo();
}
}
inputStream = manager.getInputStream();
byte[] buffer = new byte[1024 * 4];
int length = -1;
if (inputStream != null) {
while ((length = inputStream.read(buffer)) != -1 && isdownloading) {
mLocalFile.write(buffer, 0, length);
mDownLoadSize += length;
mSafeDownLoadSize = mDownLoadSize;
mHandler.sendEmptyMessage(TASK_PROGESS);
}
}
// 下载完了
if (mDownLoadSize == mFileSize) {
boolean renameResult = renameFile();
if (renameResult) {
mHandler.sendEmptyMessage(TASK_SUCCESS); // 转移文件成功
} else {
new File(mFilePath + File.separator + mFileName + ".tmp").delete();
Message msg = Message.obtain();
msg.what = TASK_ERROR;
Bundle bundle = new Bundle();
bundle.putString(ERROR_KEY, "转移文件失败");
msg.setData(bundle);
mHandler.sendEmptyMessage(TASK_ERROR);// 转移文件失败
}
// 清除数据库任务
mHelper.deleteDownLoadInfo(mSQLDownLoadInfo.getUserID(), getTaskID());
mDownLoadTask = null;
mDownLoadCallBack = null;
ondownload = false;
mDownLoadSize = 0;
mSafeDownLoadSize = 0;
}
} catch (Exception e) {
e.printStackTrace();
if (isdownloading) {
if (mIsSupportBreakpoint) {
try {
if (mLocalFile != null) {
long length = mLocalFile.length();
if (length > 0) {
saveDownloadInfo();
}
}
} catch (IOException e1) {
e1.printStackTrace();
}
}
ondownload = false;
mPool.remove(mDownLoadTask);
mDownLoadTask.stopDownLoad();
mDownLoadTask = null;
Message msg = Message.obtain();
msg.what = TASK_ERROR;
Bundle bundle = new Bundle();
bundle.putString(ERROR_KEY, e.getMessage());
msg.setData(bundle);
mHandler.sendMessage(msg);
}
} finally {
if (manager != null) {
manager.disconnect();
}
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (mLocalFile != null) {
try {
mLocalFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
代码看上去也没那么多是不是,其实也没那么简单,带着一步一坑的想法慢慢看吧。
刚开始的一个判断没什么,然后声明了ConnectionWrapperManager,这又是个什么鬼,看看后面的一些逻辑,发现原来所有下载操作都是它来完成,真是层层代理呢,关于ConnectionWrapperManager还是专门拧一个小节会比较有层次感吧。
3.ConnectionWrapperManager真面目
首先看看包结构可能够容易只管了解一点: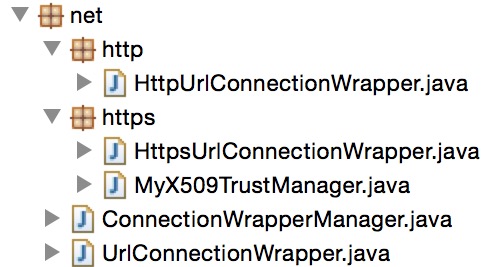
UrlConnectionWrapper是一个接口,封装了HttpsURLConnection和HttpURLConnection的各个方法:
public interface UrlConnectionWrapper {
void setRequestMethod(DownLoadManager.RequsteMethod method);
int getResponseCode();
void setDoOutPut(boolean newValue);
InputStream getInputStream();
void setConnectTimeout(int timeout);
void setReadTimeout(int timeout);
void setRequestProperty(String range, String s);
void disconnect();
long getFileSize();
}
所以这个其实就是一个适配器模式,ConnectionWrapperManager是一个适配器,它会根据URL来选择使用HttpUrlConnectionWrapper还是HttpsUrlConnectionWrapper里的相应方法,从而达到支持http和https,而HttpUrlConnectionWrapper和HttpsUrlConnectionWrapper里面当然就是调用HttpURLConnection和HttpsURLConnection的方法啦,这里只贴出HttpUrlConnectionWrapper的代码,HttpsUrlConnectionWrapper里面有一些ssl和证书等的相关处理,有兴趣的自己百度吧,不然感觉真心是越扯越远有点收不回来了。
public class HttpUrlConnectionWrapper implements UrlConnectionWrapper{
private HttpURLConnection mHttpURLConnection;
public HttpUrlConnectionWrapper(HttpURLConnection connection) {
mHttpURLConnection = connection;
}
@Override
public void setRequestMethod(DownLoadManager.RequsteMethod method) {
try {
if(method == DownLoadManager.RequsteMethod.GET){
mHttpURLConnection.setRequestMethod("GET");
} else {
mHttpURLConnection.setRequestMethod("POST");
}
} catch (ProtocolException e) {
e.printStackTrace();
}
}
@Override
public int getResponseCode() {
try {
return mHttpURLConnection.getResponseCode();
} catch (IOException e) {
e.printStackTrace();
}
return -1;
}
@Override
public void setDoOutPut(boolean newValue) {
mHttpURLConnection.setDoOutput(newValue);
}
@Override
public InputStream getInputStream() {
try {
return mHttpURLConnection.getInputStream();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
@Override
public void setConnectTimeout(int timeout) {
mHttpURLConnection.setConnectTimeout(timeout);
}
@Override
public void setReadTimeout(int timeout) {
mHttpURLConnection.setReadTimeout(timeout);
}
@Override
public void setRequestProperty(String range, String s) {
mHttpURLConnection.setRequestProperty(range, s);
}
@Override
public void disconnect() {
mHttpURLConnection.disconnect();
}
@Override
public long getFileSize() {
return mHttpURLConnection.getContentLength();
}
}
简单清楚明白吧,再来看看封装成ConnectionWrapperManager的代码:
public class ConnectionWrapperManager implements UrlConnectionWrapper{
private UrlConnectionWrapper mWrapper;
public ConnectionWrapperManager(Context context, String murl) {
try {
URL url = new URL(murl);
if (murl.startsWith("https")){
HttpsURLConnection conn = (HttpsURLConnection)url.openConnection();
mWrapper = new HttpsUrlConnectionWrapper<MyX509TrustManager, X509KeyManager, HostnameVerifier>(conn, new MyX509TrustManager(context), null, null);
} else if(murl.startsWith("http")){
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
mWrapper = new HttpUrlConnectionWrapper(conn);
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void setRequestMethod(DownLoadManager.RequsteMethod method) {
mWrapper.setRequestMethod(method);
}
@Override
public int getResponseCode() {
return mWrapper.getResponseCode();
}
@Override
public void setDoOutPut(boolean newValue) {
mWrapper.setDoOutPut(newValue);
}
@Override
public InputStream getInputStream() {
return mWrapper.getInputStream();
}
@Override
public void setConnectTimeout(int timeout) {
mWrapper.setConnectTimeout(timeout);
}
@Override
public void setReadTimeout(int timeout) {
mWrapper.setReadTimeout(timeout);
}
@Override
public void setRequestProperty(String range, String s) {
mWrapper.setRequestProperty(range, s);
}
@Override
public void disconnect() {
mWrapper.disconnect();
}
@Override
public long getFileSize() {
return mWrapper.getFileSize();
}
}
到这里我们可以明确了,ConnectionWrapperManager都是假象,其实在Downloader中操作ConnectionWrapperManager,其实是在操作HttpURLConnection和HttpsURLConnection啦。
4.DownLoader续
欢迎回来,现在我们继续看download方法里的内容了。
先通过url来openConnection生成对应的URLConnection,然后设置get还是post,超时等,这些都是套路。
当mDownLoadSize小于0的时候,就相当于是第一次下次并进行初始化执行openConnention方法。mDownLoadSize是个全局变量,下载的时候会变,而且这个值会同步数据库里的值,所以可以作为是否第一次下载的标识,当然后面还有更多用处。看看openConnention方法吧:
private void openConnention(ConnectionWrapperManager manager) {
try {
if (mFileSize == 0) {
mFileSize = manager.getFileSize();
}
if (mFileSize > 0) {
isFolderExist();
mLocalFile = new RandomAccessFile(new File(mFilePath + File.separator + mFileName + ".tmp"), "rwd");
mSQLDownLoadInfo.setDownloadSize(mFileSize);
if (isdownloading) {
saveDownloadInfo();
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
做了几件事:
- 通过
ConnectionWrapperManager获得文件的总大小,存到数据库里面去(前面说了有两个字段是还没有被赋初值的,忘了可以倒回去看看)。 - 新建下载的文件夹,不说了看代码吧。
private boolean isFolderExist() { boolean result = false; try { String filepath = mFilePath; File file = new File(filepath); if (!file.exists()) { if (file.mkdirs()) { result = true; } } else { result = true; } } catch (Exception e) { e.printStackTrace(); } return result; } 生成了一个
RandomAccessFile临时文件,这个非常牛逼,尤其是它的seek方法,可以说是断点续传的理论基础了。
如果不是第一次下载,那就判断有没有那个临时文件了,如果有,那么mDownLoadSize也肯定有值,就seek到那个值然后继续下载吧,如果没有, 就相当于是第一次下啦。
接下来就是下载更新回调的过程了,对照代码看看就行,反正都这样一个流程,再贴出来看看吧:inputStream = manager.getInputStream(); byte[] buffer = new byte[1024 * 4]; int length = -1; if (inputStream != null) { while ((length = inputStream.read(buffer)) != -1 && isdownloading) { mLocalFile.write(buffer, 0, length); mDownLoadSize += length; mSafeDownLoadSize = mDownLoadSize; mHandler.sendEmptyMessage(TASK_PROGESS); } }接下来是下载完了的操作,上代码:
// 下载完了 if (mDownLoadSize == mFileSize) { boolean renameResult = renameFile(); if (renameResult) { mHandler.sendEmptyMessage(TASK_SUCCESS); // 转移文件成功 } else { new File(mFilePath + File.separator + mFileName + ".tmp").delete(); Message msg = Message.obtain(); msg.what = TASK_ERROR; Bundle bundle = new Bundle(); bundle.putString(ERROR_KEY, "转移文件失败"); msg.setData(bundle); mHandler.sendEmptyMessage(TASK_ERROR);// 转移文件失败 }简而言之,就是下完了之后重命名一下,然后根据重命名是否成功来发起成功或者失败的回调,下面是重命名的代码:
private boolean renameFile() { File newfile = new File(mFilePath + File.separator + mFileName); if (newfile.exists()) { newfile.delete(); } File oldFile = new File(mFilePath + File.separator + mFileName + ".tmp"); return oldFile.renameTo(newfile); }然后是清理战场了:
// 清除数据库任务 mHelper.deleteDownLoadInfo(mSQLDownLoadInfo.getUserID(), getTaskID()); mDownLoadTask = null; mDownLoadCallBack = null; ondownload = false; mDownLoadSize = 0; mSafeDownLoadSize = 0;如果下载过程中出错了,也是需要清理战场的,如果支持断点续传的话,还需要把已经下载的信息保存在数据库里面去:
if (isdownloading) { if (mIsSupportBreakpoint) { try { if (mLocalFile != null) { long length = mLocalFile.length(); if (length > 0) { saveDownloadInfo(); } } } catch (IOException e1) { e1.printStackTrace(); } } ondownload = false; mPool.remove(mDownLoadTask); mDownLoadTask.stopDownLoad(); mDownLoadTask = null; Message msg = Message.obtain(); msg.what = TASK_ERROR; Bundle bundle = new Bundle(); bundle.putString(ERROR_KEY, e.getMessage()); msg.setData(bundle); mHandler.sendMessage(msg); }final里面也关闭链接,关闭文件,也算是最后的清理了:
finally { if (manager != null) { manager.disconnect(); } if (inputStream != null) { try { inputStream.close(); } catch (IOException e) { e.printStackTrace(); } } if (mLocalFile != null) { try { mLocalFile.close(); } catch (IOException e) { e.printStackTrace(); } } }好了,主要代码贴完了,需要注意的是清理的时候有个
mDownLoadTask.stopDownLoad();方法,照旧来看看:private void stopDownLoad() { isdownloading = false; if (mLocalFile != null) { long length = mSafeDownLoadSize; if (length > 0) { if (mIsSupportBreakpoint) { saveDownloadInfo(); } else { clearDownLoadInfo(); } } } Message msg = Message.obtain(); msg.what = TASK_STOP; Bundle bundle = new Bundle(); bundle.putLong(STOP_KEY, mDownLoadSize); msg.setData(bundle); mHandler.sendMessage(msg); }里面除了有个复制回调的handler发送消息外就是存储和清理数据库数据了,再来看看这两个方法:
/** * 是否支持断点续传就在于中断下载是否保存下载信息 */ private void saveDownloadInfo() { if (mIsSupportBreakpoint) { mSQLDownLoadInfo.setDownloadSize(mSafeDownLoadSize); mSQLDownLoadInfo.setFileSize(mFileSize); mHelper.save(mSQLDownLoadInfo); } } private void clearDownLoadInfo() { mDownLoadSize = 0; mDownLoadCallBack = null; mHelper.deleteDownLoadInfo(mSQLDownLoadInfo.getUserID(), getTaskID()); File file = new File(mFilePath + File.separator + mFileName + ".tmp"); if (file.exists()) { file.delete(); } }到目前为止,整个下载流程基本上也就是这个样子了,停止或者取消下载的时候这个类也提供一个公共方法来给外部调用,简单了解一下就行:
public void stop() { if (mDownLoadTask != null) { ondownload = false; mDownLoadTask.stopDownLoad(); mPool.remove(mDownLoadTask); mDownLoadTask = null; } } public void destroy() { if (mDownLoadTask != null) { mDownLoadTask.stopDownLoad(); mPool.remove(mDownLoadTask); mDownLoadTask = null; } mHelper.deleteDownLoadInfo(mSQLDownLoadInfo.getUserID(), getTaskID()); File file = new File(mFilePath + File.separator + mFileName + ".tmp"); if (file.exists()) { file.delete(); } mDownLoadSize = 0; Message msg = Message.obtain(); msg.what = TASK_STOP; Bundle bundle = new Bundle(); bundle.putLong(STOP_KEY, mDownLoadSize); msg.setData(bundle); mHandler.sendMessage(msg); }是不是看了这么多早就晕掉了,下载已经结束了,但感觉还有一块儿没有说到,是什么呢什么呢。
5.数据库
对,就是它,它比较独立,就单独拧出来了,和下载其实没啥关系,但是为下载提供了持续存储,当然不仅仅是下载,太多时候各种业务需要它来提供持续了,感觉可以从零开始学习设计数据库。
还是和上面一样,就截个类名看看就行了,这个结构稍微后面一点一点解释吧,虽然画个图会更好点。AbstractDatabaseHelper和BaseDBHelper是基类,前者提供数据库封装,后者提供业务封装。MyDatabaseHelper和DownloadTaskDBHelper分别负责继承他们,DownloadTaskDBHelper持有MyDatabaseHelper的实例,是不是觉得跟某个设计模式及其相似呢。
不说了,上代码:
public abstract class AbstractDatabaseHelper {
/** */
/**
* SQLite数据库实例
*/
public SQLiteDatabase mDb = null;
/** */
/**
* 数据库创建帮手
*/
protected CreateDBHelper mDbHelper = null;
/** */
/**
* 获得当前数据库帮手类标识(一般是该类名称),用于日志等的记录
*
* @return
*/
protected abstract String getTag();
/** */
/**
* 获得数据库名称
*
* @return
*/
protected abstract String getMyDatabaseName();
/** */
/**
* 获得数据库版本,值至少为1。 当数据库结构发生改变的时候,请将此值加1,系统会在初始化时自动调用
* createDBTables和dropDBTables方法更新数据库结构。
*
* @return
*/
protected abstract int getDatabaseVersion();
/** */
/**
* 创建数据库表的SQL语句,一个元素一条语句
*
* @return
*/
protected abstract String[] createDBTables();
/** */
/**
* 删除数据库表的SQL语句,一个元素一条语句
*
* @return
*/
protected abstract String[] dropDBTables();
/** */
/**
*
* TODO 内部数据库创建帮手类
*
*/
private class CreateDBHelper extends SQLiteOpenHelper {
public CreateDBHelper(Context ctx) {
super(ctx, getMyDatabaseName(), null, getDatabaseVersion());
}
@Override
public void onCreate(SQLiteDatabase db) {
executeBatch(createDBTables(), db);
}
@Override
public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) {
Log.e(getTag(), "Upgrading database '" + getMyDatabaseName() + "' from version " + oldVersion + " to "
+ newVersion);
for (int i = oldVersion; i < newVersion; i++) {
if (i <= 14) {
String[] tasks = { "DROP TABLE IF EXISTS UPLOAD_TASK", "DROP TABLE IF EXISTS FEED_COMMENT",
"DROP TABLE IF EXISTS SHARE", "DROP TABLE IF EXISTS MESSAGE", "DROP TABLE IF EXISTS CLIPS" };
executeBatch(tasks, db);
} else if (i <= 16) {
String[] updateClipTable = { "ALTER TABLE CLIPS ADD COLUMN FAV_ID VARCHAR(32)",
"ALTER TABLE CLIPS ADD COLUMN TYPE INTEGER" };
executeBatch(updateClipTable, db);
} else if (i <= 18) {
db.execSQL("DROP TABLE IF EXISTS MESSAGE");
} else if (i <= 19) {
db.execSQL("DROP TABLE IF EXISTS DOWNLOAD_TASK");
}
}
onCreate(db);
}
/** */
/**
* 批量执行Sql语句
*
* @param sqls
* @param db
*/
private void executeBatch(String[] sqls, SQLiteDatabase db) {
if (sqls == null)
return;
db.beginTransaction();
try {
int len = sqls.length;
for (int i = 0; i < len; i++) {
db.execSQL(sqls[i]);
}
db.setTransactionSuccessful();
} catch (Exception e) {
Log.d(getTag(), e.getMessage());
} finally {
db.endTransaction();
}
}
}
/** */
/**
* 打开或者创建一个指定名称的数据库
*
* @param dbName
* @param ctx
*/
private synchronized void open(Context ctx) {
if (mDbHelper == null) {
try {
mDbHelper = new CreateDBHelper(ctx);
mDb = mDbHelper.getWritableDatabase();
} catch (Exception e) {
Log.w("wenba", e);
}
}
}
protected void init(Context ctx) {
if (ctx == null) {
throw new RuntimeException("ctx is null");
}
if (mDbHelper == null) {
open(ctx);
}
}
/** */
/**
* 关闭数据库
*/
public void close() {
try {
if (mDb != null && mDb.isOpen()) {
mDb.close();
}
if (mDbHelper != null) {
mDbHelper.close();
}
} catch (Exception e) {
Log.w("wenba", e);
}
}
}
AbstractDatabaseHelper里面有一个CreateDBHelper的内部类来继承SQLiteOpenHelper,然后里面就是标准的一些函数的实现啦。需要主要的是onUpgrade的实现跟业务有点关系,先不管,有兴趣可以自己了解,executeBatch支持批处理SQL语句,然后创建数据库等操作都是用虚函数的形势交给子类去实现的。
那来看这个子类吧:
public class MyDatabaseHelper extends AbstractDatabaseHelper {
private static MyDatabaseHelper instance = null;
private String databaseName = "MYdb.db";
private String tag = "my_database";
private int databaseVersion = 20;
private Context context;
@Override
protected String[] createDBTables() {
String[] object = {
"CREATE TABLE IF NOT EXISTS UPLOAD_TASK(" + "ID INTEGER PRIMARY KEY AUTOINCREMENT" + ",UID VARCHAR(32)"
+ ",TASK_ID VARCHAR(100)" + ",CREATE_TIME TIMESTAMP" + ",STATUS VARHCHAR(20)"
+ ",TAKS_BEAN BLOB" + ")",
"CREATE TABLE IF NOT EXISTS FEED_DETAIL(" + "ID INTEGER PRIMARY KEY AUTOINCREMENT"
+ ",FEED_ID VARCHAR(100)" + ",UID VARCHAR(32)" + ",FEED_BEAN BLOB" + ")",
"CREATE TABLE IF NOT EXISTS SETTING(" + "ID INTEGER PRIMARY KEY AUTOINCREMENT" + ",_KEY VARCHAR(100)"
+ ",_VALUE VARCHAR(100)" + ")",
"CREATE TABLE IF NOT EXISTS FEED_COLLECT(" + "ID INTEGER PRIMARY KEY AUTOINCREMENT"
+ ",UID VARCHAR(32)" + ",FAV_ID VARCHAR(32)" + ",AID VARCHAR(32)" + ",FEED_ID VARCHAR(100)"
+ ",SUBJECT VARCHAR(8)" + ",FEED_COLLECT BLOB" + ")",
"CREATE TABLE IF NOT EXISTS FEED_COMMENT(" + "ID INTEGER PRIMARY KEY AUTOINCREMENT"
+ ",SID VARCHAR(32)" + ",UID VARCHAR(32)" + ",AID VARCHAR(32)" + ",CREATE_TIME TIMESTAMP"
+ ",FEED_COMMENT BLOB" + ")",
"CREATE TABLE IF NOT EXISTS SHARE(" + "ID INTEGER PRIMARY KEY AUTOINCREMENT" + ",UID VARCHAR(32)"
+ ",AID VARCHAR(32)" + ",SID VARCHAR(32)" + ",TYPE INTEGER" + ",CREATE_TIME TIMESTAMP"
+ ",SUBJECT VARCHAR(8)" + ",SHARE_BEAN BLOB" + ")",
"CREATE TABLE IF NOT EXISTS MESSAGE(" + "ID INTEGER PRIMARY KEY AUTOINCREMENT" + ",CATEGORY INTEGER"
+ ",MESSAGE_ID VARCHAR(32)" + ",UID VARCHAR(32)" + ",STATUS INTEGER" + ",CREATE_TIME TIMESTAMP"
+ ",MESSAGE_BEAN BLOB" + ")",
"CREATE TABLE IF NOT EXISTS CLIPS(" + "ID INTEGER PRIMARY KEY AUTOINCREMENT" + ",UID VARCHAR(32)"
+ ",ARTICLE_ID VARCHAR(32)" + ",ARTICLE_INDEX INTEGER" + ",FAV_ID VARCHAR(32)"
+ ",TYPE INTEGER" + ",CREATE_TIME TIMESTAMP" + ",CLIPS_BEAN BLOB" + ")",
"CREATE TABLE IF NOT EXISTS DOWNLOAD_TASK( " + "ID INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL"
+ ",UID VARCHAR" + ",TASK_ID VARCHAR" + ",URL VARCHAR" + ",FILE_PATH VARCHAR"
+ ",FILE_NAME VARCHAR" + ",FILE_SIZE INTEGER" + ",DOWNLOAD_SIZE INTEGER"
+ ",IS_SUPPORT_BREAKPOINT INTEGER" + ")",
"CREATE TABLE IF NOT EXISTS TEST_CENTER( " + "ID INTEGER PRIMARY KEY AUTOINCREMENT"
+ ",UID VARCHAR(32)" + ",CENTER_ID VARCHAR(100)" + ",SUBJECT VARCHAR(32)" + ",CENTER_BEAN BLOB"
+ ")" };
return object;
}
@Override
protected String[] dropDBTables() {
String[] object = { "DROP TABLE IF EXISTS UPLOAD_TASK", "DROP TABLE IF EXISTS FEED_DETAIL",
"DROP TABLE IF EXISTS SETTING", "DROP TABLE IF EXISTS FEED_COLLECT",
"DROP TABLE IF EXISTS FEED_COMMENT", "DROP TABLE IF EXISTS SHARE", "DROP TABLE IF EXISTS MESSAGE",
"DROP TABLE IF EXISTS CLIPS", "DROP TABLE IF EXISTS DOWNLOAD_TASK", "DROP TABLE IF EXISTS CLIPS",
"DROP TABLE IF EXISTS TEST_CENTER" };
return object;
}
@Override
protected String getMyDatabaseName() {
return databaseName;
}
@Override
protected int getDatabaseVersion() {
return databaseVersion;
}
@Override
protected String getTag() {
return tag;
}
private static synchronized void initSyn(Context context) {
instance = new MyDatabaseHelper(context);
}
public static MyDatabaseHelper getInstance(Context context) {
if (instance == null) {
initSyn(context);
}
return instance;
}
private MyDatabaseHelper(Context context) {
this.context = context;
}
public void execSQL(String sql, Object[] bindArgs) {
init(context);
if (mDb == null) {
return;
}
try {
mDb.execSQL(sql, bindArgs);
} catch (Exception e) {
Log.w("wenba", e);
}
}
public void execSQL(String[] sql, Object[][] bindArgs) {
if (sql == null || sql.length == 0) {
return;
}
init(context);
if (mDb == null) {
return;
}
for (int i = 0; i < sql.length; i++) {
try {
mDb.execSQL(sql[i], bindArgs[i]);
} catch (Exception e) {
Log.w("wenba", e);
}
}
}
public void execSQL(String sql) {
init(context);
if (mDb == null) {
return;
}
try {
mDb.execSQL(sql);
} catch (Exception e) {
Log.w("wenba", e);
}
}
public void update(String table, ContentValues values, String whereClause, String[] whereArgs) {
init(context);
if (mDb == null) {
return;
}
try {
mDb.update(table, values, whereClause, whereArgs);
} catch (Exception e) {
Log.w("wenba", e);
}
}
public Cursor rawQuery(String sql, String[] selectionArgs) {
init(context);
if (mDb == null) {
return null;
}
return mDb.rawQuery(sql, selectionArgs);
}
public Cursor query(String table, String[] columns, String selection, String[] selectionArgs, String groupBy,
String having, String orderBy) {
init(context);
if (mDb == null) {
return null;
}
return mDb.query(table, columns, selection, selectionArgs, groupBy, having, orderBy);
}
}
子类除了根据业务创建了一大堆表之外,也实现了增删改查相关操作,通过名为mDb的SQLiteDatabase来进行操作,mDb是在父类初始化的时候就初始化好了的,可以代码倒回去看看,其他的也没什么了,接着看另外一个父类:
public abstract class BaseDBHelper<T> {
protected String getUserId() {
String userId = "12345";//UserManager.getCurUserId();
if (userId == null) {
return null;
}
return userId;
}
public abstract String getTable();
public abstract void save(T obj);
public abstract void update(T obj);
public abstract void delete(String id);
public abstract void deleteAll();
public abstract T find(String uid, String taskId);
public abstract int getCount();
public abstract List<T> getAllData();
}
UID是根据业务账号系统生成保存的,这里就用一个简单字符串代替就行了。就是一堆虚函数,这些就跟业务相关了,相当与这些方法会封装刚刚MyDatabaseHelper里面实现的增删改查方法。最后就是DownloadTaskDBHelper了:
public class DownloadTaskDBHelper extends BaseDBHelper<DownLoadBean> {
private static final String TABLE_NAME = "DOWNLOAD_TASK";
private static final int MAX_SAVE_TIME = 5;
private volatile static DownloadTaskDBHelper mInstance;
private MyDatabaseHelper mHelper;
private int saveTime;
private DownloadTaskDBHelper(Context context) {
mHelper = MyDatabaseHelper.getInstance(context);
}
public static DownloadTaskDBHelper getInstance(Context context) {
if (mInstance == null) {
synchronized (DownloadTaskDBHelper.class) {
if (mInstance == null) {
mInstance = new DownloadTaskDBHelper(context);
}
}
}
return mInstance;
}
@Override
public String getTable() {
return TABLE_NAME;
}
@Override
public void save(DownLoadBean obj) {
String sql = "insert into " + getTable() + "(" + "UID,TASK_ID,URL,FILE_PATH,FILE_NAME,FILE_SIZE,DOWNLOAD_SIZE,IS_SUPPORT_BREAKPOINT"
+ ")values(?,?,?,?,?,?,?,?)";
Object[] bindArgs = { obj.getUserID(), obj.getTaskID(), obj.getUrl(), obj.getFilePath(), obj.getFileName(), obj.getFileSize(), obj.getDownloadSize(),
obj.isSupportBreakpoint() == true ? 1 : 0 };
Cursor cursor = null;
try {
cursor = mHelper.rawQuery("SELECT * FROM " + getTable() + " WHERE UID = ? AND TASK_ID = ? ", new String[] { obj.getUserID(), obj.getTaskID() });
if (cursor.moveToNext()) {
update(obj);
} else {
mHelper.execSQL(sql, bindArgs);
}
} catch (Exception e) {
saveTime++;
if (saveTime < MAX_SAVE_TIME) {
save(obj);
} else {
saveTime = 0;
}
} finally {
if (cursor != null) {
cursor.close();
}
}
saveTime = 0;
}
@Override
public void update(DownLoadBean obj) {
String selection = null;
String[] selectionArgs = null;
selection = "UID = ? AND TASK_ID = ?";
selectionArgs = new String[] { obj.getUserID(), obj.getTaskID() };
ContentValues cv = new ContentValues();
cv.put("URL", obj.getUrl());
cv.put("FILE_PATH", obj.getFilePath());
cv.put("FILE_NAME", obj.getFileName());
cv.put("FILE_SIZE", obj.getFileSize());
cv.put("DOWNLOAD_SIZE", obj.getDownloadSize());
mHelper.update(getTable(), cv, selection, selectionArgs);
}
public List<DownLoadBean> findUserDownLoadInfo(String userID) {
List<DownLoadBean> list = new ArrayList<DownLoadBean>();
String sql = "SELECT * FROM " + getTable() + " WHERE UID = ?";
Cursor cursor = null;
try {
cursor = mHelper.rawQuery(sql, new String[] { userID });
while (cursor.moveToNext()) {
DownLoadBean downloadinfo = new DownLoadBean();
downloadinfo.setUserID(cursor.getString(cursor.getColumnIndex("UID")));
downloadinfo.setTaskID(cursor.getString(cursor.getColumnIndex("TASK_ID")));
downloadinfo.setUrl(cursor.getString(cursor.getColumnIndex("URL")));
downloadinfo.setFilePath(cursor.getString(cursor.getColumnIndex("FILE_PATH")));
downloadinfo.setFileName(cursor.getString(cursor.getColumnIndex("FILE_NAME")));
downloadinfo.setFileSize(cursor.getLong(cursor.getColumnIndex("FILE_SIZE")));
downloadinfo.setDownloadSize(cursor.getLong(cursor.getColumnIndex("DOWNLOAD_SIZE")));
downloadinfo.setIsSupportBreakpoint(cursor.getLong(cursor.getColumnIndex("DOWNLOAD_SIZE")) > 0 ? true : false);
list.add(downloadinfo);
}
} catch (Exception e) {
Log.w("wenba", e);
} finally {
if (cursor != null) {
cursor.close();
}
}
return list;
}
public DownLoadBean findDownLoadInfo(String userID, String taskID) {
DownLoadBean downloadinfo = null;
String sql = "SELECT * FROM " + getTable() + " WHERE UID = ? AND TASK_ID = ?";
Cursor cursor = null;
try {
cursor = mHelper.rawQuery(sql, new String[] { userID, taskID });
while (cursor.moveToNext()) {
downloadinfo = new DownLoadBean();
downloadinfo.setUserID(cursor.getString(cursor.getColumnIndex("UID")));
downloadinfo.setTaskID(cursor.getString(cursor.getColumnIndex("TASK_ID")));
downloadinfo.setUrl(cursor.getString(cursor.getColumnIndex("URL")));
downloadinfo.setFilePath(cursor.getString(cursor.getColumnIndex("FILE_PATH")));
downloadinfo.setFileName(cursor.getString(cursor.getColumnIndex("FILE_NAME")));
downloadinfo.setFileSize(cursor.getLong(cursor.getColumnIndex("FILE_SIZE")));
downloadinfo.setDownloadSize(cursor.getLong(cursor.getColumnIndex("DOWNLOAD_SIZE")));
downloadinfo.setIsSupportBreakpoint(cursor.getLong(cursor.getColumnIndex("DOWNLOAD_SIZE")) > 0 ? true : false);
}
} catch (Exception e) {
Log.w("wenba", e);
} finally {
if (cursor != null) {
cursor.close();
}
}
return downloadinfo;
}
public List<DownLoadBean> findAllDownLoadInfo() {
List<DownLoadBean> list = new ArrayList<DownLoadBean>();
String sql = "SELECT * FROM " + getTable();
Cursor cursor = null;
try {
cursor = mHelper.rawQuery(sql, new String[] {});
while (cursor.moveToNext()) {
DownLoadBean downloadinfo = new DownLoadBean();
downloadinfo.setUserID(cursor.getString(cursor.getColumnIndex("UID")));
downloadinfo.setTaskID(cursor.getString(cursor.getColumnIndex("TASK_ID")));
downloadinfo.setUrl(cursor.getString(cursor.getColumnIndex("URL")));
downloadinfo.setFilePath(cursor.getString(cursor.getColumnIndex("FILE_PATH")));
downloadinfo.setFileName(cursor.getString(cursor.getColumnIndex("FILE_NAME")));
downloadinfo.setFileSize(cursor.getLong(cursor.getColumnIndex("FILE_SIZE")));
downloadinfo.setDownloadSize(cursor.getLong(cursor.getColumnIndex("DOWNLOAD_SIZE")));
downloadinfo.setIsSupportBreakpoint(cursor.getLong(cursor.getColumnIndex("DOWNLOAD_SIZE")) > 0 ? true : false);
list.add(downloadinfo);
}
} catch (Exception e) {
Log.w("wenba", e);
} finally {
if (cursor != null) {
cursor.close();
}
}
return list;
}
public void deleteAllDownLoadInfo() {
String sql = "DELETE FROM " + getTable();
mHelper.execSQL(sql);
}
public void deleteUserDownLoadInfo(String userID) {
String sql = "DELETE FROM " + getTable() + " WHERE UID = \"" + userID + "\"";
mHelper.execSQL(sql);
}
public void deleteDownLoadInfo(String userID, String taskID) {
String sql = "DELETE FROM " + getTable() + " WHERE UID = \"" + userID + "\" AND TASK_ID = \"" + taskID + "\"";
mHelper.execSQL(sql);
}
@Override
public void delete(String id) {
}
@Override
public void deleteAll() {
}
@Override
public DownLoadBean find(String uid, String taskId) {
return findDownLoadInfo(uid, taskId);
}
@Override
public int getCount() {
return 0;
}
@Override
public List<DownLoadBean> getAllData() {
return findAllDownLoadInfo();
}
}
现在回去看下载的数据库相关操作,是不是就恍然大悟了,或者是标红的代码都不红了哈哈。
6.总结
很长的一篇,基本上把所有代码都贴上来,本来就是以应用为导向,所以这样也是必须的,能把这些代码组合在一起就可以跑起来了。
如果想把APP做大,那么下载模块和数据库模块都是必不可缺的,知道原理很重要,会应用也很重要,平时积累自己的兵器库关键时候随拿随用就更重要了,啊哈。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至same4869@126.com


